이 글은 CUDA 기반 GPU 병럴처리 프로그래밍 책의 내용을 바탕으로 정리한 글이다.
chapter 2 - 3에서 핵심은 프로그램 구조와 흐름이다. 시간을 쪼개서 쓰는 글이다보니, 뜨문 뜨문 올리긴하지만, 끝까지 다 정리는 할 예정이다. 물론 기본적인 문법이나, 예제는 다루지 않을 생각이다.
CUDA 프로그램 구조 및 흐름
CUDA 프로그램 구조 ( Host vs Device )
매우 기초적이지만 중요한 부분이다. cuda 프로그램은 host 코드와 device 코드로 나누어 진다. host는 cpu를 사용하고, system memory를 사용하고, device는 CUDA core를 사용하고 Device memory( video memory 등 여러 명칭이 있음 )를 사용한다.
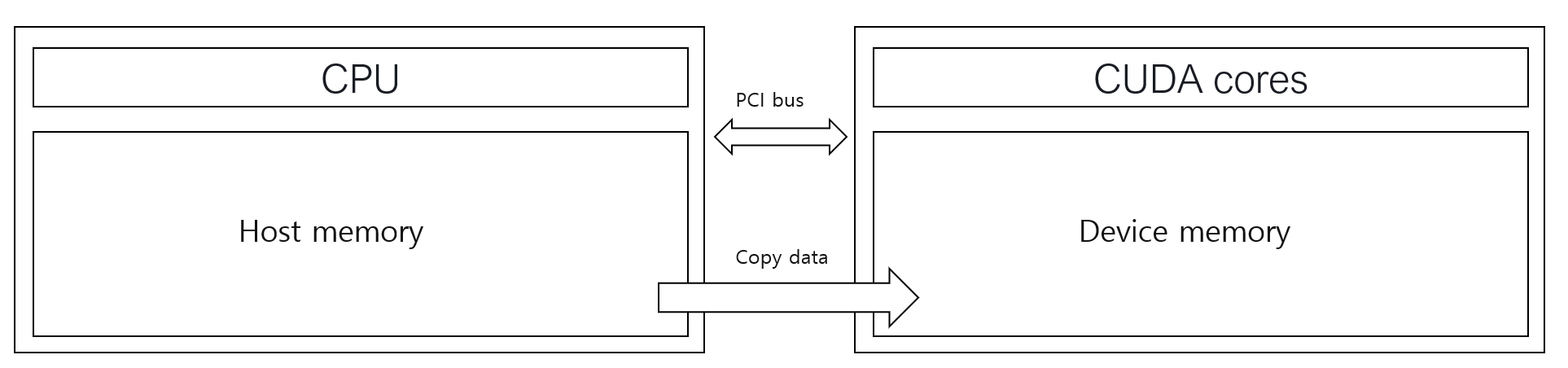
이 그림을 반드시 기억하면 좋다. CPU와 GPU는 서로 분리되어 있고, 통신을 통해 데이터를 주고 받아야 한다.
CUDA 프로그램 흐름
1. 모든 데이터는 host 메모리에 저장되어 있다.
2. device memory로 host 메모리에 저장된 데이터를 복사해준다.
3. host 코드에서 커널을 호출하여 gpu 연산을 한다.
4. 해당 결과를 device memory에서 host memory로 복사해 온다.
5. 사용된 모든 memory를 해제한다.
이 흐름은 CUDA 프로그래밍을 한다면, 알아야할 가장 기본적인 흐름이다. 그럼 단계에 따라 해야할 일을 세부적으로 생각해보면 아래와 같다. 문법적인 요소는 설명하지 않겠다.
1. 모든 데이터는 host 메모리에 저장되어 있다.
- 데이터에 접근할 * ( 포인터 변수 ), 데이터를 저장할 memory size, 해당 공간의 초기화 및 데이터 생성 or 복사
( c ++ 의 new 와 memset 을 사용하여 초기화하고, data를 for 문등을 이용해 copy 혹인 generation 한다 )
2. device memory로 host 메모리에 저장된 데이터를 복사해준다.
- device에 접근할 * ( 포인터 ) 변수를 설정하고 cudaMalloc 으로 메모리를 할당해주고, cudaMemeset 으로 초기화 후에, cudaMemcpy 를 통해 HostToDevice로 데이터를 복사해준다.
2번에 대해 조금만 더 부가 설명을 하지만, 코드를 짜다보면 자연히 class로 밖에 구현하게 될 거다. 즉, 2 번 부분은 나 같은 경우, 생성자 부분에서 처리해준다. 물론 소멸자 부분에서 cudaFree를 해주는 것 역시 밝혀둔다.
3. host 코드에서 커널을 호출하여 gpu 연산을 한다.
- Kernel call을 통해 gpu연산을 한다. 이 때, Kernel의 제어권을 gpu로 넘겨야하기 때문에, kernel funtion의 global로 해야한다. 또한 linux 에서 coding을 하면 gpu와 cpu의 연산이 비동기로 돌기 때문에 kernel funtion 수행 후에 cudaDeviceSyncronize()를 통해 kernel funtion의 실행을 보장해준다.
3번을 설명함에 있어 조금 더 설명하겠다. 물론, 이 책에서 처음 사용되는 벡터 합 예제에서는 cudaDeviceSyncronize() 를 사용하지 않고, 시간 측정 부분의 chapter에서 처음 보여준다. 그런데 실제 병렬 처리 코드를 짜다보면, 해당 코드가 성능 저하를 일으키는 부분임을 알 수 있다. 즉, cudaDeviceSyncronize()는 남발하면 코드의 성능이 크게 저하된다. 또한, 이 코드를 사용하지 않는 경우에도, cudaMemcpy와 같은 함수는 동기화를 보장한다. 여튼, 해당 문법이 사용되어야 하는 경우의 간단한 예시를 들어보자면, (a+b) * (c+d) 를 구하는 연산을 병렬로 구현한다고 하면 더하기가 끝나는 시점에 cudaDeviceSyncronize()가 한 번 필요하다. 다만 전제는 모든 연산이 gpu에서 돈다는 가정이다. 여튼, 하고 싶은 말은 동기화를 보장하는 코드는 남발하지 말란거다.
4. 해당 결과를 device memory에서 host memory로 복사해 온다.
- cudaMemecpy를 통해 DeviceToHost 로 host의 정보를 가져온다.
5. 사용된 모든 memory를 해제한다.
- c++의 경우 delete, gpu의 경우 cudaFree로 메모리를 해제해준다.
가장 기본적인 흐름이지만 이 부분들은 내가 어떤 cuda c 코드를 짜든 들어가는 부분이다. 이 부분은 책에 나온 부분은 아니지만 메모리 할당은 생성자에, 해제는 소멸자에 넣어주고, 각각의 변수는 member 변수로 관리한다. 다른 방법이 있거나 좋은 구조가 있으면 댓글로 달아주면 참 감사할것 같다.
이 부분에서 하나 꼭 기억해야 할 점은 데이터를 복사하는 부분이 시간이 생각보다 오래 걸린다. app 최적화 코드를 짤때, input data를 1920 x 1080 짜리 data를 288 x 288로 넘기는 부분이 있다고 예를 들어보면, 이 경우 데이터를 모두 넘겨 resize까지 모두 gpu에서 처리하기보다, 288x288로 preprocess하고 넘기는 것이 더 효과적일 수 있다. 물론 시간을 찍어봐야 정확히 알 수 있는 부분이지만, 간단한 연산은 cpu로 처리하는 것이 훨씬 효율적이다. 카메라 input이 30 FPS로 들어온다고 하면, cpu에서 multi thread로 resize하는 부분을 짜고 resize하고 input을 넘기는게 효과적일 수 있다. 물론 preprocess 모두를 cpu에서 할지 일부를 gpu에서 할지는 해당 operator가 최적화된 정도에 따라 다르겠지만.
'CUDA C' 카테고리의 다른 글
| [ CUDA 기반 GPU 병렬처리 프로그래밍 ] chapter 4-5 스레드 계층, 레이아웃과 인덱싱 2 (0) | 2023.11.09 |
|---|---|
| [ CUDA 기반 GPU 병렬처리 프로그래밍 ] chapter 4-5 스레드 계층, 레이아웃과 인덱싱 1 (0) | 2023.11.08 |
| [ CUDA 기반 GPU 병렬처리 프로그래밍 ] chapter 1 GPGPU 및 병렬처리 개요 (2) | 2023.11.01 |


